マーケティング担当者以外が検索エンジンのアルゴリズムについて知っておくべきこと
2020/09/03
多くの人がアルゴリズムや機械学習を信用していないのは、それらが実際にどのように動作するかを完全に理解していないからだ。それを分解してみましょう。
------------------------------------------
本記事は下記記事の日本語訳になります。
What Non-Marketers Need to Know About Search Engine Algorithms
------------------------------------------
本記事は下記記事の日本語訳になります。
What Non-Marketers Need to Know About Search Engine Algorithms
------------------------------------------
ここ数年ソーシャルメディアを利用したことのある人なら、アルゴリズム、トラッキング、人工知能、機械学習について、一般の(マーケティング業務に携わらない)人々の間で疑いの目が高まっていることに気付いただろう。
その恐怖は理にかなっている。
何かがどのように機能しているかを正確に理解していない場合、それらのプログラムから期待しているものを正確に得られないと、負の力が働いているように見えることがある。
たとえばトランプ大統領は、Twitterのトレンドトピックが彼に偏っていることを示唆するツイートを定期的に発信している。
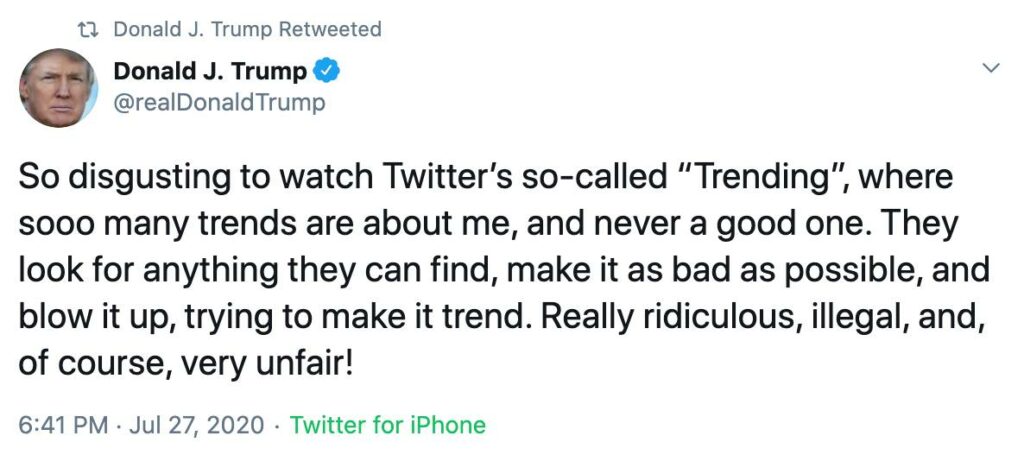
さらに最近では、Facebookの友人たちの間で、3桁の数字と「新しいケース」という言葉を検索すると、COVID事件に関するニュースが正確な数字とともに表示されるというコメントスレッドを見た。
政治的、医学的な関係はさておき、根本的な問題は、人々がアルゴリズムや機械学習を信頼していないのは、彼らが実際にどのように動作するかを完全に理解していないからだということが多い。
それでは、検索、ソーシャルメディア、その他の日常的に使用している一般的なテクノロジーアプリケーションなどでこれらがどのように機能するかについて、基本的な概要を説明する。
アルゴリズムはまだ偏っている可能性がある
しかし、実際に掘り下げる前に、アルゴリズム、機械学習モデル、人工知能は、それらを開発するプログラマによってバイアスされる可能性があることを理解することが重要だ。
しかし、率直に言って、彼らはしばしば権力者や多数派(彼らはしばしば機械学習モデルを作っている―そして彼ら自身の暗黙のバイアスに気付いていないからだ)に偏っている。
これについては、Search Engine Journalで私の他の作品をチェックしてみてください。
これらのアルゴリズムがどのように機能するかに影響するオリジナルの入力に加えて、MLとAIの性質は、ユーザが貢献する入力が結果にも影響することを意味する(この件については後ほど詳しくお話する)。
つまり、機械学習モデルはソーシャルメディアの検索や利用方法を学習し、その情報に基づいて検索結果をカスタマイズするということだ。
私たちが探していた正確なピザのレシピを見つけることができれば、それは素晴らしいことのように思えるが、重要な情報を探していて、私たちの情報源から偏見のない答えを得ていないときは、それほど素晴らしいことではない。
しかし、率直に言って、彼らはしばしば権力者や多数派(彼らはしばしば機械学習モデルを作っている―そして彼ら自身の暗黙のバイアスに気付いていないからだ)に偏っている。
これについては、Search Engine Journalで私の他の作品をチェックしてみてください。
これらのアルゴリズムがどのように機能するかに影響するオリジナルの入力に加えて、MLとAIの性質は、ユーザが貢献する入力が結果にも影響することを意味する(この件については後ほど詳しくお話する)。
つまり、機械学習モデルはソーシャルメディアの検索や利用方法を学習し、その情報に基づいて検索結果をカスタマイズするということだ。
私たちが探していた正確なピザのレシピを見つけることができれば、それは素晴らしいことのように思えるが、重要な情報を探していて、私たちの情報源から偏見のない答えを得ていないときは、それほど素晴らしいことではない。
基本レベルでのアルゴリズムの動作
ウェブ上のアルゴリズムと機械学習の背後にある本質的なポイントは、人間の脳の意思決定プロセスを再現することだ―人間が必要な情報と時間をすべて取り込み、自分で分類する必要はない。
人間の思考プロセスへの近道になるはずだ。
最も基本的なレベルでは、アルゴリズムはコンピュータの中で非常に速く実行されるif-thenステートメントであり、Aを実行するとBが返され、Cを実行するとDが返される。
知り合いに「どちらのご出身ですか。」と聞いてみてください。
その答えに基づいて、あなたの頼みの綱となる選択肢がある。
子供の頃からの故郷だと言われても、今まで行ったことのない場所から来たと言われた場合とはかなり違った反応をするだろう。
人間の思考プロセスへの近道になるはずだ。
最も基本的なレベルでは、アルゴリズムはコンピュータの中で非常に速く実行されるif-thenステートメントであり、Aを実行するとBが返され、Cを実行するとDが返される。
知り合いに「どちらのご出身ですか。」と聞いてみてください。
その答えに基づいて、あなたの頼みの綱となる選択肢がある。
子供の頃からの故郷だと言われても、今まで行ったことのない場所から来たと言われた場合とはかなり違った反応をするだろう。
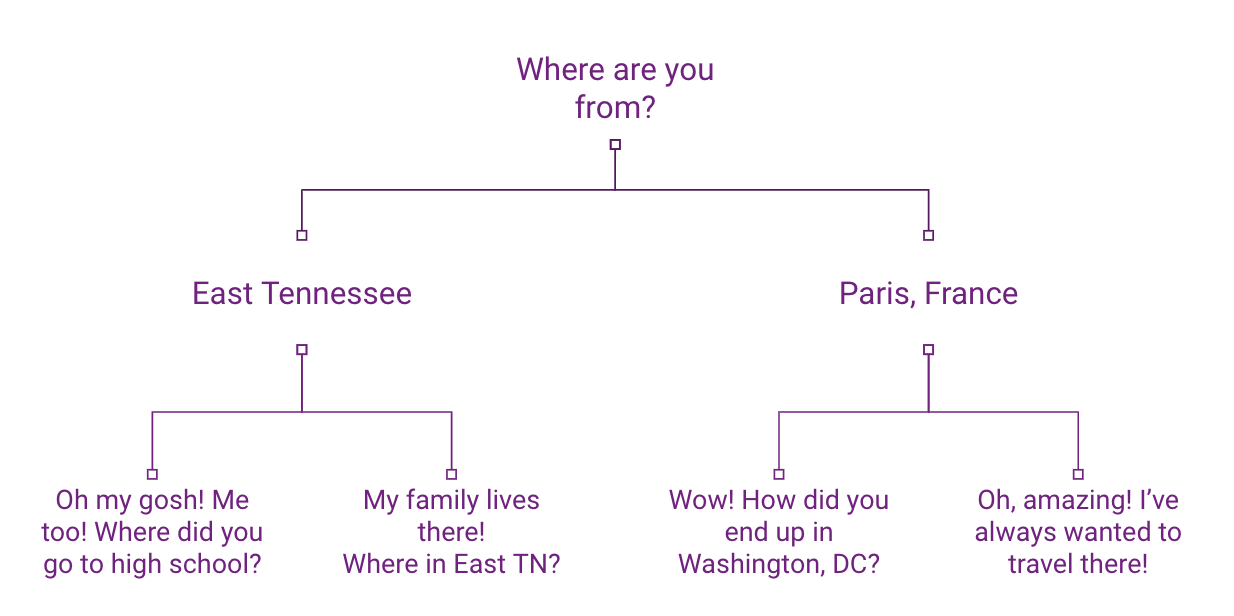
これは、アルゴリズムの動作を単純化したものです。
しかし、その考え方は、それぞれの経路が特定の方法を導き、コンピューターがワークフローや公式に従って次のステップに進むというものだ。
Googleで何かを検索すると、同じようなことが起こる。
「シカゴピザ」で検索すると、Googleがあなたについて持っている情報、あなたの位置情報、そしてあなたの検索履歴に基づいて、シカゴピザのレシピを教えてくれたり、どのレストランがシカゴのピザを出しているかを教えてくれたりする。
しかし、その考え方は、それぞれの経路が特定の方法を導き、コンピューターがワークフローや公式に従って次のステップに進むというものだ。
Googleで何かを検索すると、同じようなことが起こる。
「シカゴピザ」で検索すると、Googleがあなたについて持っている情報、あなたの位置情報、そしてあなたの検索履歴に基づいて、シカゴピザのレシピを教えてくれたり、どのレストランがシカゴのピザを出しているかを教えてくれたりする。
機械学習とは?
機械学習の背後にある最も基本的な考え方は、入力した入力がアルゴリズムの将来の推奨や結果に影響を与える可能性があるということだ。
最も基本的なレベルでは、アルゴリズムはユーザーの好みを 「学習」 し、次回if-thenステートメントを使用するときにそれらを考慮する。
例えば、Google NewsやFacebookのおすすめページなどに表示される。
これらのソースとのやり取りの仕方に基づいて、アルゴリズムはあなたが好むと思われるものを提示しようとする。
例えば、私がたくさんの動物救助ページ(Facebook上でそのように分類している)をフォローしていると、私が本当に犬の養子縁組を気にしていることをアルゴリズムが「学習」する。
そこからターゲット広告(ドッグフード、ドッグトイ、ドッグベッド)と、他のページのおすすめ、見るビデオ、参加するグループを表示する。
逆の場合もあります。あなたがクリックしたり、否定的な記事や(何が言われているのかを見るためだけでも)反対の記事をたくさん読んだりした場合、アルゴリズムはクリックを判断するだけで、必ずしもあなたの意図が背後にあるとは限らない。
つまり、ユーザーがクリックしたコンテンツのようなコンテンツが表示されるようになると、それはプログラミングとユーザーのアクションに基づいてのみ行われる。
ドナルド・トランプがこのニュースは偏っていると非難したとき、彼が目にするニュースの多くがアルゴリズムが彼のオンライン行動から学んだことに基づいてパーソナライズされていることを彼は理解していないだろう。
もし彼がネガティブな目で見られる記事をたくさん読んでいたら、Google Newsは彼の読みたい記事だと判断し、そのような記事をもっと配信するだろう。機械学習のキャッチ22だ。
最も基本的なレベルでは、アルゴリズムはユーザーの好みを 「学習」 し、次回if-thenステートメントを使用するときにそれらを考慮する。
例えば、Google NewsやFacebookのおすすめページなどに表示される。
これらのソースとのやり取りの仕方に基づいて、アルゴリズムはあなたが好むと思われるものを提示しようとする。
例えば、私がたくさんの動物救助ページ(Facebook上でそのように分類している)をフォローしていると、私が本当に犬の養子縁組を気にしていることをアルゴリズムが「学習」する。
そこからターゲット広告(ドッグフード、ドッグトイ、ドッグベッド)と、他のページのおすすめ、見るビデオ、参加するグループを表示する。
逆の場合もあります。あなたがクリックしたり、否定的な記事や(何が言われているのかを見るためだけでも)反対の記事をたくさん読んだりした場合、アルゴリズムはクリックを判断するだけで、必ずしもあなたの意図が背後にあるとは限らない。
つまり、ユーザーがクリックしたコンテンツのようなコンテンツが表示されるようになると、それはプログラミングとユーザーのアクションに基づいてのみ行われる。
ドナルド・トランプがこのニュースは偏っていると非難したとき、彼が目にするニュースの多くがアルゴリズムが彼のオンライン行動から学んだことに基づいてパーソナライズされていることを彼は理解していないだろう。
もし彼がネガティブな目で見られる記事をたくさん読んでいたら、Google Newsは彼の読みたい記事だと判断し、そのような記事をもっと配信するだろう。機械学習のキャッチ22だ。
騙そうとしていないアルゴリズム
テクノロジー企業やその他の大企業に不信感を抱いている人の中には、アルゴリズムや機械学習モデルが進歩して独自の思考を持つようになったと信じている人がかなりいるようだ。
われわれは今まで以上にiRobotに近づいているかもしれないが、検索エンジンの結果はユーザーをだましたり現実を歪めたりするよう意図的に作られたものではない。
そしてしばしば得られる結果は純粋に数学に基づいています。
例えば、「新しいケース」というキーワードで任意の3桁の数字を検索すると、Googleはその正確な数字と新しいCOVIDケースの結果を表示するので、それらの数字は本質的に虚偽であると確信している人のFacebookの投稿を見た。
われわれは今まで以上にiRobotに近づいているかもしれないが、検索エンジンの結果はユーザーをだましたり現実を歪めたりするよう意図的に作られたものではない。
そしてしばしば得られる結果は純粋に数学に基づいています。
例えば、「新しいケース」というキーワードで任意の3桁の数字を検索すると、Googleはその正確な数字と新しいCOVIDケースの結果を表示するので、それらの数字は本質的に虚偽であると確信している人のFacebookの投稿を見た。
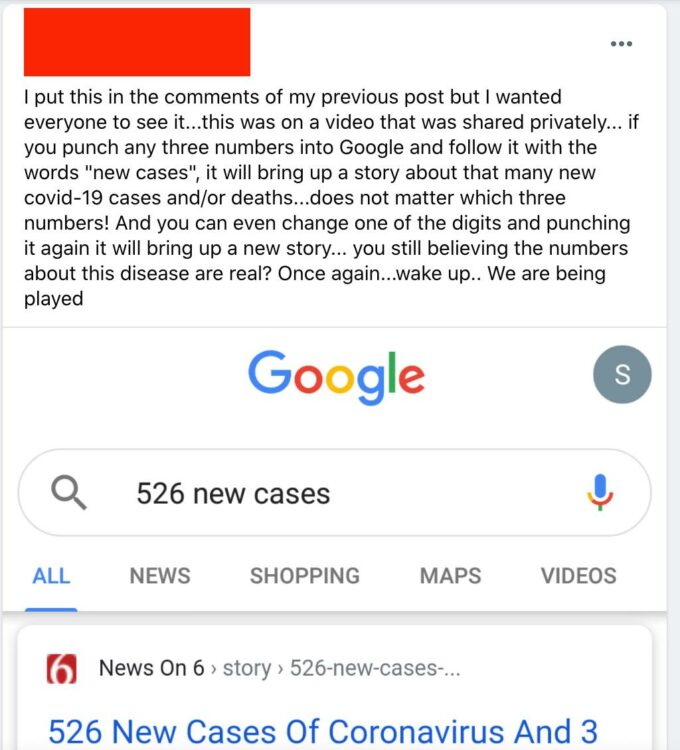
しかし、今回のケースは、統計的に見て、非常に多くの情報源が非常に高い割合でデータを公開しているため、Googleがこれらの数字のいずれかで結果を見つけるのに十分な情報がウェブ上にあることを示している。
統計的に見て、もしあらゆる位置情報エンティティ(町、市、郡、州、地域、州、国)が一定の間隔(毎日、毎週、毎月、四半期ごと)でCOVID番号を公開していれば、GoogleやBing、その他の検索エンジンでその番号や「新規症例」を検索すると、1桁、2桁、3桁、4桁、さらには5桁のCOVIDニュース結果が出ることは避けられない。
Googleに任意の数字を入力して「新しいケース」を実際に証明しているのは、アルゴリズムが検索エンジンのウェブページのライブラリに保存されている情報に基づいて、ウェブサイトからのニュースリリースデータを「読み取って」「理解して」、それを検索者にフィードバックすることができるということだけだ。
特に、それはあなたの検索の質問と正確に一致するだろうし、検索エンジンはあなたが探しているものを想定しているからだ。
あなたが必要としていたものを正確に手に入れることができ、素晴らしい仕事をしたと思う。
この観点から見ると、検索エンジンやソーシャルメディアは、あなたが投げた棒をあなたに返す「いい子」であり、あなたの自由を奪い、あなたのお金をすべて奪おうとする犯罪の首謀者ではない。
検索エンジンは、ユーザーにとって最も関連性の高い結果を検索者として取得するように構築されています(検索やクリック履歴、適時性、関連性など、多くの要素に基づいている。)。
だから、オンラインで何かの情報を見つけることができるからといって、陰謀論を証明するものではない(できない場合もある!)
統計的に見て、もしあらゆる位置情報エンティティ(町、市、郡、州、地域、州、国)が一定の間隔(毎日、毎週、毎月、四半期ごと)でCOVID番号を公開していれば、GoogleやBing、その他の検索エンジンでその番号や「新規症例」を検索すると、1桁、2桁、3桁、4桁、さらには5桁のCOVIDニュース結果が出ることは避けられない。
Googleに任意の数字を入力して「新しいケース」を実際に証明しているのは、アルゴリズムが検索エンジンのウェブページのライブラリに保存されている情報に基づいて、ウェブサイトからのニュースリリースデータを「読み取って」「理解して」、それを検索者にフィードバックすることができるということだけだ。
特に、それはあなたの検索の質問と正確に一致するだろうし、検索エンジンはあなたが探しているものを想定しているからだ。
あなたが必要としていたものを正確に手に入れることができ、素晴らしい仕事をしたと思う。
この観点から見ると、検索エンジンやソーシャルメディアは、あなたが投げた棒をあなたに返す「いい子」であり、あなたの自由を奪い、あなたのお金をすべて奪おうとする犯罪の首謀者ではない。
検索エンジンは、ユーザーにとって最も関連性の高い結果を検索者として取得するように構築されています(検索やクリック履歴、適時性、関連性など、多くの要素に基づいている。)。
だから、オンラインで何かの情報を見つけることができるからといって、陰謀論を証明するものではない(できない場合もある!)
しかしマーケティングは結果に影響を与える
検索エンジンとソーシャルメディアの問題は、提供される結果が他の人間によって作られていることだ。
検索結果を検証する技術は増えているが(フェイスブックでの事実調査が好きだ)、検索エンジン最適化やソーシャルメディアマーケティングの基本的な知識を持っている人なら誰でも、それらの結果に影響を与えることができる。
この事実は、結果を熟読する際に心に留めておくだけでも重要だ。
マーケティングとパーソナライゼーションデータは、現代の技術プラットフォームがユーザーから利益を得るために最善を尽くすことを意味する。
そのため、ユーザーは何かを考えて、その日のうちにFacebookの広告を受け取ることになるかもしれない。
アルゴリズム、機械学習、マーケティングパーソナライゼーションがどのように機能するかを基本的に理解するだけで、ウェブ上のコンテンツをより多くの情報に基づいて消費することができる。
これらのプロセスは、多くの場合、保存された好みによって通知されるif-thenプログラムであることを念頭に置くことによって、私たちは、技術に関する誤った情報と戦うことを助けることができ、より多くの検索者とソーシャルメディアユーザーを、彼らをより良く前進させる方法に関与させることができる。
検索結果を検証する技術は増えているが(フェイスブックでの事実調査が好きだ)、検索エンジン最適化やソーシャルメディアマーケティングの基本的な知識を持っている人なら誰でも、それらの結果に影響を与えることができる。
この事実は、結果を熟読する際に心に留めておくだけでも重要だ。
マーケティングとパーソナライゼーションデータは、現代の技術プラットフォームがユーザーから利益を得るために最善を尽くすことを意味する。
そのため、ユーザーは何かを考えて、その日のうちにFacebookの広告を受け取ることになるかもしれない。
アルゴリズム、機械学習、マーケティングパーソナライゼーションがどのように機能するかを基本的に理解するだけで、ウェブ上のコンテンツをより多くの情報に基づいて消費することができる。
これらのプロセスは、多くの場合、保存された好みによって通知されるif-thenプログラムであることを念頭に置くことによって、私たちは、技術に関する誤った情報と戦うことを助けることができ、より多くの検索者とソーシャルメディアユーザーを、彼らをより良く前進させる方法に関与させることができる。
本サイト管理人の感想
正直AIも機械学習も自分で作れないからいまいち何ができるのか把握しきれていないところがある。自分で作れるところまでいくとそれはそれでもう仕事になりそうだ。

図解即戦力 機械学習&ディープラーニングのしくみと技術がこれ1冊でしっかりわかる教科書
株式会社アイデミー 山口達輝 (著), 株式会社アイデミー 松田洋之 (著)
出版日 2019/9/2
出版社 技術評論社
出版日 2019/9/2
出版社 技術評論社
Recent Entries
-
2021/09/24
転職活動の記録 -おすすめ転職エージェント、サイト-
-
2020/09/15
「数字」が読めると本当に儲かるんですか?を読んでの感想レビュー
-
2020/09/15
ストーリーでわかる財務3表超入門を読んでの感想レビュー
-
2020/09/15
Google、荒らしから検索結果を守るための新たな対策を発表
Categories
著者について

小堀 慎平
国家資格キャリアコンサルタント
上級ウェブ解析士
TOEIC950
キャリアやマーケティングについて書いています。
上級ウェブ解析士
TOEIC950
キャリアやマーケティングについて書いています。